

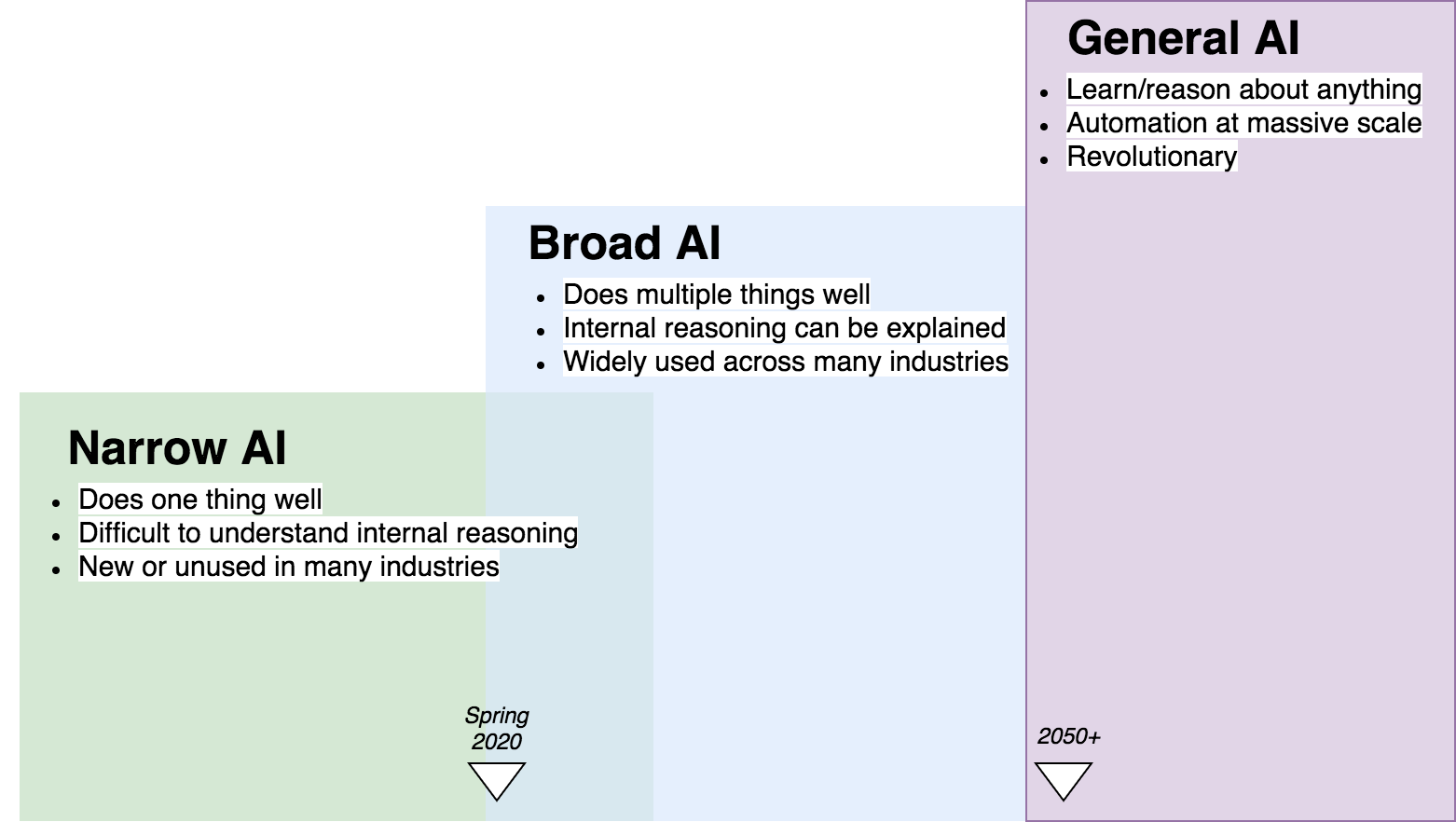
AI1 is going through a transition. Tremendous research and business interest within the last decade has pushed the technology to the beginning of a new era. Going through the broad phase has the potential to disrupt every known major industry. However, despite the attention AI has received, it is still largely unused.
A recent O’Reilly report states 22% of professionals see “lack of institutional support” as the biggest impediment to AI adoption. Another 20% believe it to be “difficulties in identifying appropriate business use cases”. It could be argued that these two problems are correlated. Organization leaders are going to support technology they believe is good at solving concrete and relevant problems. Thus, if a legitimate use case is presented then getting support from higher up and building cultural interest is easier.
Real Examples
Entity Detection
- Clearview.ai offers tools to law enforcement to help search for persons of interest.
- Google Photos automatically generates metadata detailing the content, location, and mood of each photo.
- MammoScreen helps radiologists review mammograms for signs of breast cancer. It is one of dozens of medical algorithms approved by the FDA.
Data Analysis
- Volt Capital Management attributes a 24% annual return on their hedge fund to a proprietary machine learning model2.
- A recent AI strategy report from NOAA states they have seen significant performance and efficiency gains in areas such as “weather warning generation” and “processing, interpretation, and utilization of earth observations”.
- Chematica is a software that finds new chemical reaction chains which reproduce existing drugs. This process is called retrosynthesis and can be used to find cheaper methods of making medicine or circumvent pharmaceutical patents.
Media Processing
- Disney’s Pixar uses deep learning3 to denoise frames in their rendering pipeline. Their paper highlights its use in films like Coco and Frozen.
- Krisp is an app that removes background noise from microphone input.
- A notorious product of deep learning termed Deepfake convincingly replaces the likeness (i.e. complexion, movement, voice) of a person in a video with another.
Natural Language
- Deep learning and other techniques have unlocked a new way for users to interact with applications. Natural language interfaces like the Google Assistant, Amazon Alexa, and Apple Siri have grown by the billions in the last decade.
- Grammarly offers “AI-Powered” writing assistance that dwarfs traditional spelling and grammar checking. The company is valued at over a billion dollars and has been profitable most of its existence.
Real-time Systems
- Tesla’s autopilot system has been partially enabled and improving since 2015.
- Attendees of Blizzard Entertainment’s annual gaming convention in 2019 could compete against an AI better than 98.8% of players. On the surface this application may seem like a gimmick, yet foreshadowed the ability of future systems, and provided novel entertainment for paying fans.
Create Your Own

The flowchart is intended to guide a solution discovery process. Follow the steps to drill down to the foundation of each problem and link it with a solution space. The blue boxes represent domains where AI has been implemented successfully.
Limitations

Current supervised-learning4 models struggle to understand unusual contexts or mixtures of the concepts they learn through training. A person can identify a guitar no matter if it’s at a rock concert or at the bottom of a swimming pool. Modern algorithms might rely too heavily on the contextual information to determine that the guitar is a shark swimming at the bottom of the pool. This is because the model is unable to acquire generic understanding and there are no underwater guitar examples in the training data set.

An out of distribution sample does not need to be obvious to the human eye in order to exploit vulnerabilities. As seen above, subtle noise into a neural network5 can cause neural pathways to misfire. This vulnerability poses serious issues beyond misidentifying stop signs. For example, racial bias against black patients was recently uncovered in healthcare software making recommendations to hospitals and insurers for millions of people. Issues like this can arise when the dataset used to build a model does not align with a real world input-output pair. It is necessary to include random perturbation and diversity in training data, termed data augmentation, to improve the resistance to natural variance and adversarial attacks.
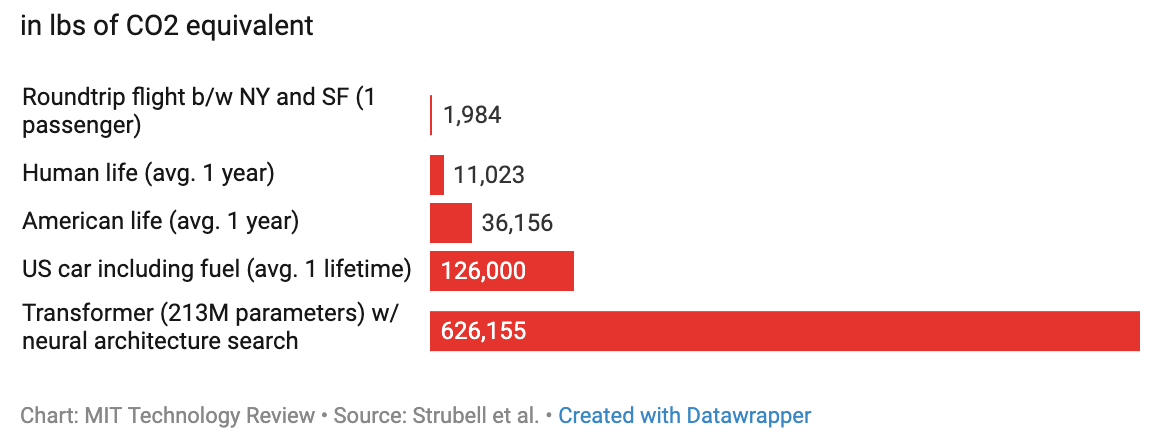
Deep learning in particular is known for requiring lots of compute and time. A report from the University of Massachusetts, Amherst estimates the carbon footprint of neural architecture search and training to be as much as five cars. OpenAI Five required over 10,000 years worth of in-game training in order to defeat the world’s best teams.
To AI’s credit, it does not have millions of years of evolution backing its architecture and initialization like humans do. The field is aggressively working toward better generalization and reduction of training time. Additionally, there is an emerging sub-field focusing on new methods to reduce carbon overhead. However, it can take months or even years before production environments enjoy the fruits of new research.

Standard deep learning models can learn primitives very well. For example, shape, color, material, and size. However, encoding knowledge of primitives and the ability to reason about them may require major architectural redesign. The sub-field of Symbolic AI seeks to resolve the fundamental entanglement of concepts and reasoning.
As was mentioned in our previous post, much of modern AI struggles to be interpreted in how it works and makes decisions. For example, many algorithms have been created to help doctors diagnose patients faster and more accurately. However, doctors struggle to trust the diagnosis because the software is unable to provide the reasoning behind its decision. It is even difficult for experts to understand the algorithms they create.
Emerging Solutions
Data Analysis
- DeepMind has predicted COVID-19 protein structures will provide an “important resource for understanding how it functions” because “experiments to determine the structure can take months or longer.”
- There are an estimated hundred million landmines and unexploded munitions among areas of conflict in the world. Fortunately, research out of Binghamton University in New York introduces a model capable of locating and mapping the explosives from aerial imagery.
Natural Language
- OpenAI’s commercial API has entered beta. It is built upon their GPT-3 model with 173 billion parameters enabling the API to learn from only a few examples and handle tasks that are impossible with competing NLP/NLU services.
Meta
- Neurosymbolic AI proposed by the MIT-IBM Lab combines deep learning with classical symbolic theory to achieve artificial reasoning never before possible. For example, this could support tools for using natural language to make complex data queries.
- Google Brain recently published their work of evolving machine learning algorithms from scratch. This is a meta use case where machine learning is used to create new and improved machine learning algorithms from basic mathematical operations.
Real-time Systems
- Fine motor control continues to be a major challenge in robotics. However, the future of robot dexterity looks positive thanks to OpenAI’s research into manipulating objects with a single hand.
Conclusion
New investment and passion within the last decade has boosted AI to the next level. Despite its limitations, the technology is proven to work in countless environments across many industries. Is your organization preparing for the disruption of Broad AI? Do you need help implementing a use case or gaining institutional support? We are here to help! Please reach out at hello@cantina.co.
-
The meaning of artificial intelligence (AI) is precisely the sum of its two parts. Something artificial is of unnatural origin, while intelligence is the ability to acquire, retain, and apply information. Thus, the complete definition of artificial intelligence is the unnaturally occurring ability to acquire, retain, and apply information. AI is valuable because it automates tasks that ordinarily require human or beyond-human ability. In theory, almost everything we do and wish we could do as humans, can be performed by an artificial system. ↩
-
Machine learning (ML) is a process by which a computer system improves itself through experience. ML can also refer to the field of study that examines this process. Using ML, the optimization of a system or the expansion of its capabilities can be automated and accelerated. Imagine practicing a song on the piano but time moves a lot faster, you never get tired, and you can seamlessly share knowledge with fifty of your clones who are also practicing. ↩
-
Deep learning (DL) is any type of learning by a system with multiple artificial neural network layers. DL excels with inputs and outputs that demand complicated processing and abstract correlations. For example, facial recognition, real-time music composition, and pharmaceutical discovery. ↩
-
Supervised learning (SL) is a type of machine learning where a system approximates a function based on example input-output pairs. SL embeds correlations into a system so that it can make informed estimations. Estimations can be about anything - from when the rain starts, to who unlocks a phone, to how an author might write the remainder of an unfinished passage. ↩
-
An Artificial Neural Network (ANN) is made up of connected nodes called neurons. A connection allows a signal to be sent from one neuron to another. A “signal” is a real number computed by some nonlinear function of a neuron’s inputs. An ANN is essentially a multivariable calculator. For example, one could be configured to convert celsius to fahrenheit, or compute the volume of a pyramid. ↩


