

AI. This is a field that’s been around for a while.
Theories on the processes of cognition date back centuries. The first computer programs to mimic human behavior were invented in the 50s and 60s. Throughout its history AI has seen periods of stagnation, even occasional disillusionment, punctuated by great strides as new barriers and presumed limitations were breached. “Expert Systems”, “Logic Programming” and “Knowledge Engineering” had their eras and fueled many advances throughout AI’s history. Remember when a program named Deep Blue beat Chess GrandMaster Gary Kasparov? And another from IBM named Watson winning handily at Jeopardy and marvelling Alex Trebek?
Back in the stone ages I cobbled up “intelligent” bots that “understood English” (not really) with UNIX tools Lex and YACC. Then some drawing programs that maintained constraints and rules made with the parenthesis-laden language Lisp which (like Scheme and others) was designed for symbolic processing, and has been extensively utilized in the AI research field. I did similar explorations of Prolog that I ported to AmigaDOS (anyone remember the Amiga?). Prolog was a breakthrough as it was designed for handling facts and rules as an approach to logical and language processing and is still widely used. (I enlightened a friend Peter Gabel onto Prolog back then, and he went on to create the company Arity to sell industrial strength Prolog32.)
Well recently, a new kind of AI has burst onto the scene.
and is propelling new discoveries in every corner of knowledge and information. This new AI can pwn the best game playing champions, it can learn to drive cars, and it can spot you in a crowd. Today your speech can be translated instantly into Cantonese because of this tech wizardry. And these new methods could potentially perceive intelligence on other worlds, predict stock futures and election outcomes, and discover cures for illness and extend our lives. This new era of advanced reasoning is marked by the neural network and is driven by machine learning techniques. This is truly the hot new paradigm for discovery today wherein a configuration of logic elements can be literally taught to improve its performance leading in some cases to Chappie-like capabilities that surpass even those of their makers.
Machine learning and deep learning (which are essentially synonymous and differ in complexity) are becoming important in virtually every industry where perceiving, pinpointing and predicting patterns from masses of information are key to success. To begin to make the most of these new approaches that are sure to impact your business it’s important to get an idea why this technology evolved and how it works.
Machine learning and the neural network are actually older AI ideas.
that have been enabled and radically renewed by two distinct changes that have occurred especially during the last ten years. Over the last decade two significant advances have catalyzed an explosion of growth and interest in all things having to do with AI. The first change is the rapid advance in power of computing processors, especially those traditionally used for intensive real time computer graphics as these GPUs have acquired the raw power to grind through math and numbers at speeds previously requiring a government contract to achieve. Highly parallel processors have, for example, fueled the growth in blockchained cryptocurrencies because the mechanisms to assure incontrovertible ownership require data mining of the sort necessitating intensive number-crunching power. The latest generation of TPU (tensor processing units) are specifically designed to blaze through the sometimes billions of calculations needed to train a deep neural network to understand, for example, what it is that you are saying and to learn to create art and to spot how a dancer is moving wrongly.
The second decade-long change has been brought to us by the expanding internet. It is the accumulation of the sheer amount of data that has been uploaded and recorded due what are now billions of computers and sensors all over the planet. In the last decade we have seen the rise of YouTube, social media, music, art, photography, databases, shared research and every form of raw data streamed and collected from every corner of the planet about literally everything going on moment to moment every day. Every other human is connected to the internet and there is now too much information for a 10-digited anthropoid to absorb, understand and process, so new approaches to finding patterns and categorizing information and predicting outcomes is required across every discipline you can imagine. And this trend will increase exponentially with the advent of IoT (internet of things) processors with increasing compute power tucked into and watching everything from every corner of the world.
How do these new AI achieve these feats of “understanding”.
seeing what we are unable to within unimaginable volumes of numbers, tweets, images, and videos? First we need to train an AI to do these things that we cannot. So how can some software be made to learn and improve and perform amazing feats of acuity? How can order be made from seeming chaos? Almost all of AI today is focused on the mechanisms of machine learning (ML) which is a way to achieve deeper insight into many aspects of our overly complex world.
Machine learning utilizes the connections of elements called perceptrons. A perceptron is a pretty simple thing. It receives some number of input values and produces an output value as a result. That’s all it does. The magic of machine learning is a perceptron can be taught to produce any output value desired from whatever input values are supplied.
Lots of perceptrons connected together in layers, with the outputs of one layer leading to inputs of the next, form a kind of web. This interconnected web of layers is called a neural network. And so the neural network itself receives a set of inputs and produces one or many values as output.
In order to train all the perceptrons in a neural network every connection can be thought of as like a knob on a giant mixer panel. The neural network starts out knowing nothing with all the knobs set to random values.
At this point, someone must train the network. The training step is where we supply the inputs of the network with examples we know about, and watch to see if the output produced is what’s expected.
The inputs to a neural network are called “features”.
and figuring out the salient features of the data being analyzed within a specific domain is a challenge of neural network design. A feature engineer identifies and extracts values from the mass of available data and prepares that data for the input perceptrons of the neural network itself. And from the output perceptrons is delivered some values.
If the result is wrong (almost always it will be wrong) then knobs get tweaked. And all the tweaking, all the fiddly dialing, depends on distributing a measure of the network’s ‘wrongness’ back through all the misdialed knobs that are slightly adjusted. There are higher order math tricks for figuring out how to do this, but the main point is: huge numbers of numbers must be generated from a huge number of numbers, and the latest processors can do that effortlessly now.
The training continues with samples of input producing incorrect outputs but over time, as the dials are adjusted the network will begin to produce results that are expected, and if other settings are balanced properly the model produced will be able to perform some tasks better than a human is able to.
So how can this work?
How can a very comprehensible thing like a network of perceptrons figure out who your friends are in an Instagram post? To understand that well would require more than a thousand-word blog post and more likely a course at Stanford or MIT. But a way to start to think about what is going on is to understand that the knobs of the neural network and the training are attempting to discover the shape of an exceedingly-complex mathematical function that exists in many dimensions. Kind of like the blind men who learn to conceptualize an elephant by touching it.

A neural network is trying to understand the shape or topology of a function that exists in a universe with huge numbers of degrees of freedom. Not simply the 2- or 3-dimensional functions we drew in school on graph paper. We are talking perhaps thousands of dimensions that are represented by structures called tensors, which is an entity (like a vector) that can represent a location within these inconceivable spaces. The tensors hold the values of the settings of the knobs and can be operated on in parallel by TPUs and are thus are able to achieve today’s amazing results at speeds not previously realized.
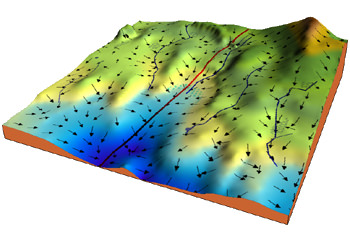
So next time you find yourself swearing at Siri, annoyed with Alexa, and fed up with Google Assistant, just understand that it is because some perceptrons need a bit more tweaking. Sooner or later all the dials will be set right and they’ll finally have the shape of the elephant that represents what you figured out.
Learn More:
Daniel Shifman is a talented educator and he can show you exactly how perceptrons work.
Also check out But what is a Neural Network? from the fantastic 3blue1brown neural network series.


